The Architecture of ASKAR
1.ASKAR(Automotive oSeK AutosaR)
ASKAR is firstly a OSEK/VDX OS223 confirmed RTOS, planed to support AUTOSAR OS standard laterly if ASKAR really becomes famous. This page will illustrate the design concept of ASKAR.
2.Task Scheduler of ASKAR
Scheduler is the most important core component of a RTOS, it decides the schedule policy. The common schedule policy for a RTOS is generally priority based, always serves the high priority task firstly, such as ucOS_II which just allow only one task per priority, and for those RTOS that allow multiply tasks per priority, such as freertos, an additionaly schedule policy is that apply time budget based round-robin policy for tasks with same priority.
And the OSEK/VDX OS223 standard defined a another kind of priority based scheduler, for only one task per priority, the scheduler acting the same with the common RTOS such as ucOS_II, but for multiply tasks per priority, the behavior is different with other common RTOS such as freertos, generally it can be illustrate as the below Figure 2.2. And note that OSEK OS can be divided into 4 conformance class show as Figure 2.1.
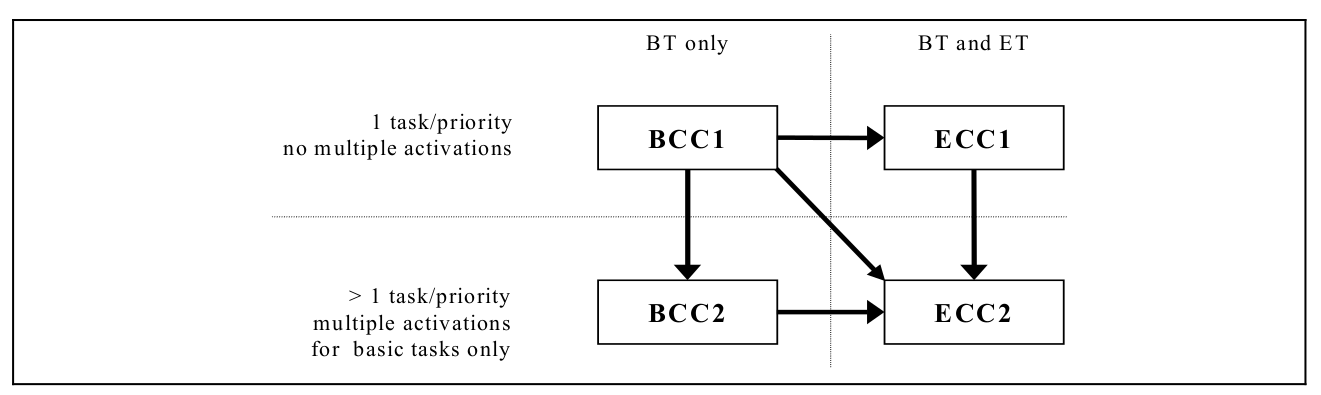
- Figure 2.1 OSEK OS Conformance Class
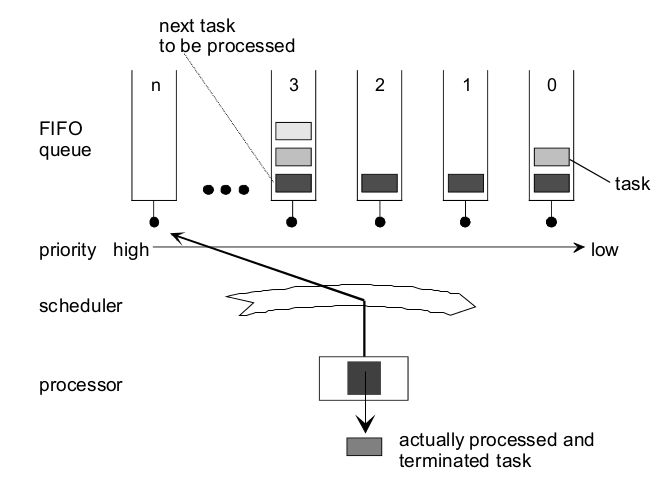
- Figure 2.2 OSEK OS Scheduler
Seeing the Figure 2.2, most out of common way to implement it is just as what you see that use priority based FIFO queues which is just I originally implemented in GaInOS. But really, there is another way that I will tell in chapter 2.1, this is not my idea, I borrow it from trampoline and re-implement it in ASKAR.
2.1 Bubble up/down method based ready queue
Different with the priority based FIFO queues that for each priority it will has a ready queue to record the ready tasks that by the order of activation time, first activated first served, the bubble up/down method based ready queue is just one queue for all tasks(with same or different priorities), let’s give an example, for the tasks showed as below Table 2.1.1.
| Task Name | Task Priority | Task Max Activation |
|---|---|---|
| T1 | 1 | 2 |
| T2 | 2 | 2 |
| T3 | 4 | 2 |
| T4 | 4 | 2 |
| T5 | 5 | 2 |
| T6 | 2 | 3 |
- Table 2.1.1 tasks examples
So a ready queue with size 12(summary of tasks’ max activation) is needed. If by the order [T1->T3->T5->T2->T6->T4->T3] to activete tasks during OS startup , it’s awlays hope that to server the task with the order [T5->T3->T4->T3->T2->T6->T1].
No matter what, it can be implemented, but implement it in a proper good clever way is somehow difficult, it need you to think. I think the way invented by trampoline is very good, it’s easy to get the point by reading the source code of sched-bubble.c of ASKAR. Here is the details.
First of all, there is a ready queue that will be sorted by the key priority which is the combation of task’s priority and activation time. Yes, that the activation time is added to the key priority for the consideration of that there are several task’s that has the same priority for the puopose to achive the goal fist in first out to be served by CPU.
How could it possible, below macro NEW_PRIORITY will be used to calculate the key priority when task activated, so it will have N bits(determined by SEQUENCE_MASK) to store the decreased activation sequence value(activation time) of that priority, and the N will be the proper range of bits to be able to store the maximum summary task activations of each priority, for the above example, priority 2 has task T2 and T6 maximum summary activations is 5(2+3), so 3 bits need to store the activation sequence value, so let’s start to see what will the queue looks like when activate tasks by the order [T1->T3->T5->T2->T6->T4->T3], follow the code logic of sched-bubble.c, and let’s assume all the PriSeqVal for each priority is 1.
#define NEW_PRIORITY(prio) (((uint16)(prio)<<SEQUENCE_SHIFT)|((--PrioSeqVal[prio])&SEQUENCE_MASK))
Activate Task T1, so its activate time will be 0, and according to API Sched_AddReady, it will be add to tail of queue, as now it was empty, so it will looks like this [T1(1,0)].
Activate Task T3, first it will be add to the tail, [T1(1,0)->T3(4,0)]], and then do Sched_BubbleUp, finally the queue looks like this [T4(4,0)->T1(1,0)].
Activate Task T5, first it will be add to the tail, [T4(4,0)->T1(1,0)->T5(5,0)], and then do Sched_BubbleUp, by 2 time swap, the queue will be [T5(5,0)->T4(4,0)->T1(1,0)].
Activate Task T2, first it will be add to the tail, [T5(5,0)->T4(4,0)->T1(1,0)->T2(2,0)], and then do Sched_BubbleUp, but really according to the logic, it will do no any swap, still the same as [T5(5,0)->T4(4,0)->T1(1,0)->T2(2,0)].
Activate Task T6, first it will be add to the tail, [T5(5,0)->T4(4,0)->T1(1,0)->T2(2,0)->T6(2,7)], and then do Sched_BubbleUp, by 1 time swap, the queue will be [T5(5,0)->T4(4,0)->T6(2,7)->T2(2,0)->T1(1,0)].
Here, you could see, oh no, from the above 2 steps queue is really out of order, but you should note that not matter how many task activated, the one with highest priority will be always be placed at the head, and it will be served firstly, and as there is Sched_BubbleDown, it will make sure that when the first high priority task get to be served by API Sched_GetReady, it will get another high priority task to the head.
Here what the most important thing is that how to determine which is the highest one, for example for T6(2,7) and T2(2,0), and then you need to check the API Sched_RealPriority, for task with same priority, the task first activated will get a bigger value(activation time - PrioSeqVal), so for T6(2,7), it will get 0, for T2(2,0), it will get 1(it’s really rely on the math of overflow), so T2 is with higher priority then T6. Here you may would say, oh what if ‘overflow’ of PrioSeqVal, here ‘overflow’ means that PrioSeqVal equals to one of its priority task’s activation time which is already in the ready queue(and you should note that overflow from 0 to it’s maximum value does have any effect as you can see from the example T2 and T6). okay, it’s over consideration as that we have make sure that “it will have N bits(determined by SEQUENCE_MASK) to store the decreased activation sequence value(activation time) of that priority”, so this “overflow” is never possible, this is really a trick.
static inline uint16 Sched_RealPriority(uint16 priority)
{
uint16 real,tmp;
real = priority>>SEQUENCE_SHIFT;
tmp = priority&SEQUENCE_MASK;
/* equals to
* if(tmp > PrioSeqVal[real])
* tmp=tmp - PrioSeqVal[real];
* else
* tmp=SEQUENCE_MASK+tmp+1-PrioSeqVal[real];
* so it was the sequence decreased value after the activation of <real>,
* bigger value means higher priority.
*/
tmp = (tmp - PrioSeqVal[real])&SEQUENCE_MASK;
real = (real<<SEQUENCE_SHIFT)|tmp;
return real;
}
For more better understanding, you can check the test case ctest_askar_01.c/ctest_askar_01.oil, this case test the above activation sequence 10000 times and it pass, the steps below to build and run:
./ctest.py ctest_askar_01
export TARGET=ctest_askar_01
# CASE is one of [Standard-with-full-preemptive, Standard-with-mixed-preemptive, Extended-with-full-preemptive, Extended-with-mixed-preemptive]
export CASE=Standard-with-full-preemptive
export qemuparams=
make all
make test
2.2 per priority based FIFO ready queues
okay, this is original implemented in my privious GaInOS, the idea is somehow the same with freertos, and for the purpose to find the highest ready priority, the idea of ucOS_II has also been borrowed. so firstly, it will have a 4 bits ReadyGroup and 4*8 bits ReadyGroupTable and 32x8 bits ReadyMapTable as below Figure 2.2.1 shows, and this is for the purpose to support 255 kind priorities, the priority value 255 is treated as INVALID_PRIORITY by ASKAR so not 256 kind.
And then, for each priority it will has an array queue to hold the ready task in a FIFO way, check the Figure 2.2.1, and follow the example about what will the queue of priority 3 looks like form time t0 to t7.
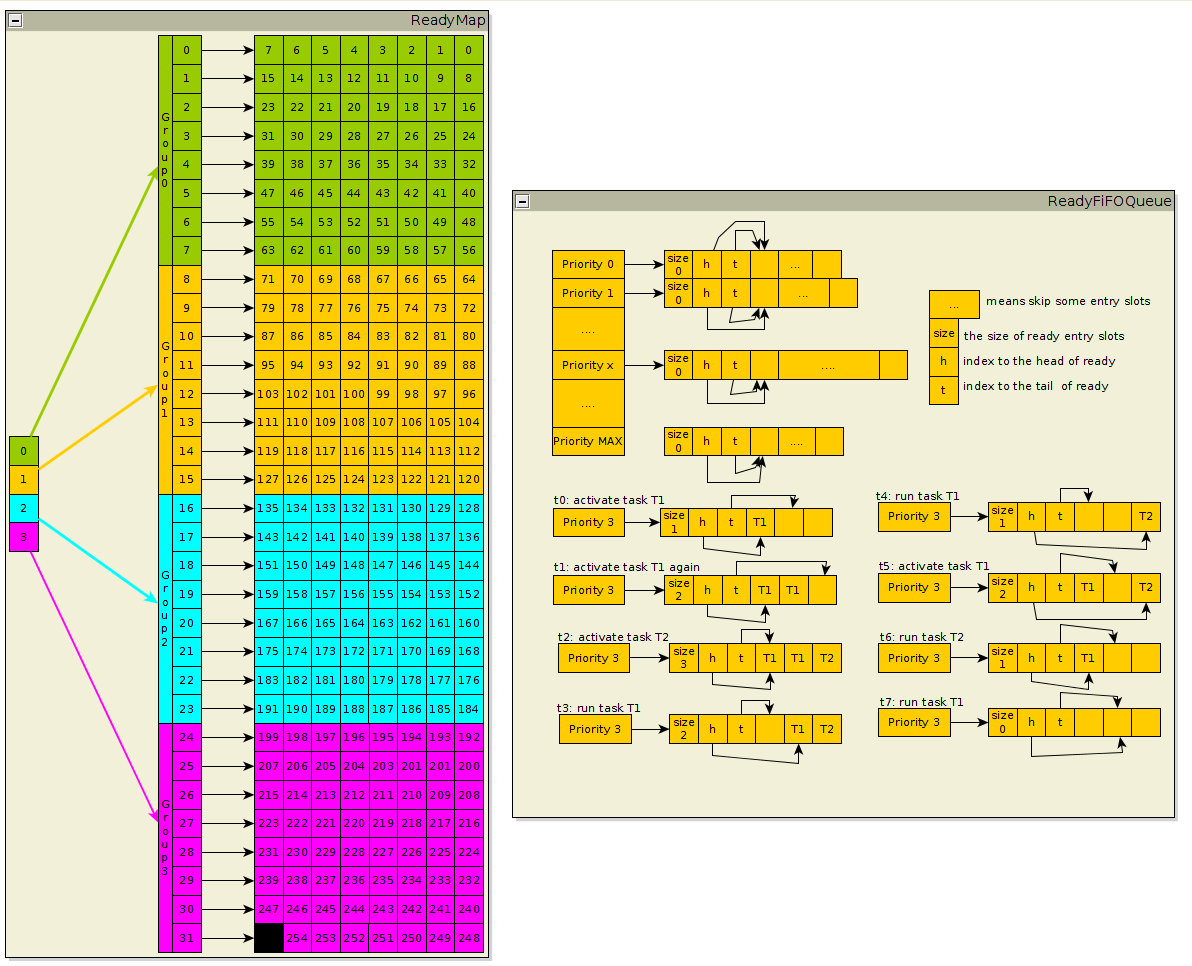
- Figure 2.2.1 Ready Map and Ready Queue
